mirror of
https://github.com/edalcin/BiodiversidadeDadosMetadados.git
synced 2024-05-15 06:32:48 -03:00
Update 20230321-maldicaoTabelas.md
This commit is contained in:
@@ -20,7 +20,7 @@ Alguns conjuntos e dados sobre biodiversidade podem ser melhor representados sob
|
||||
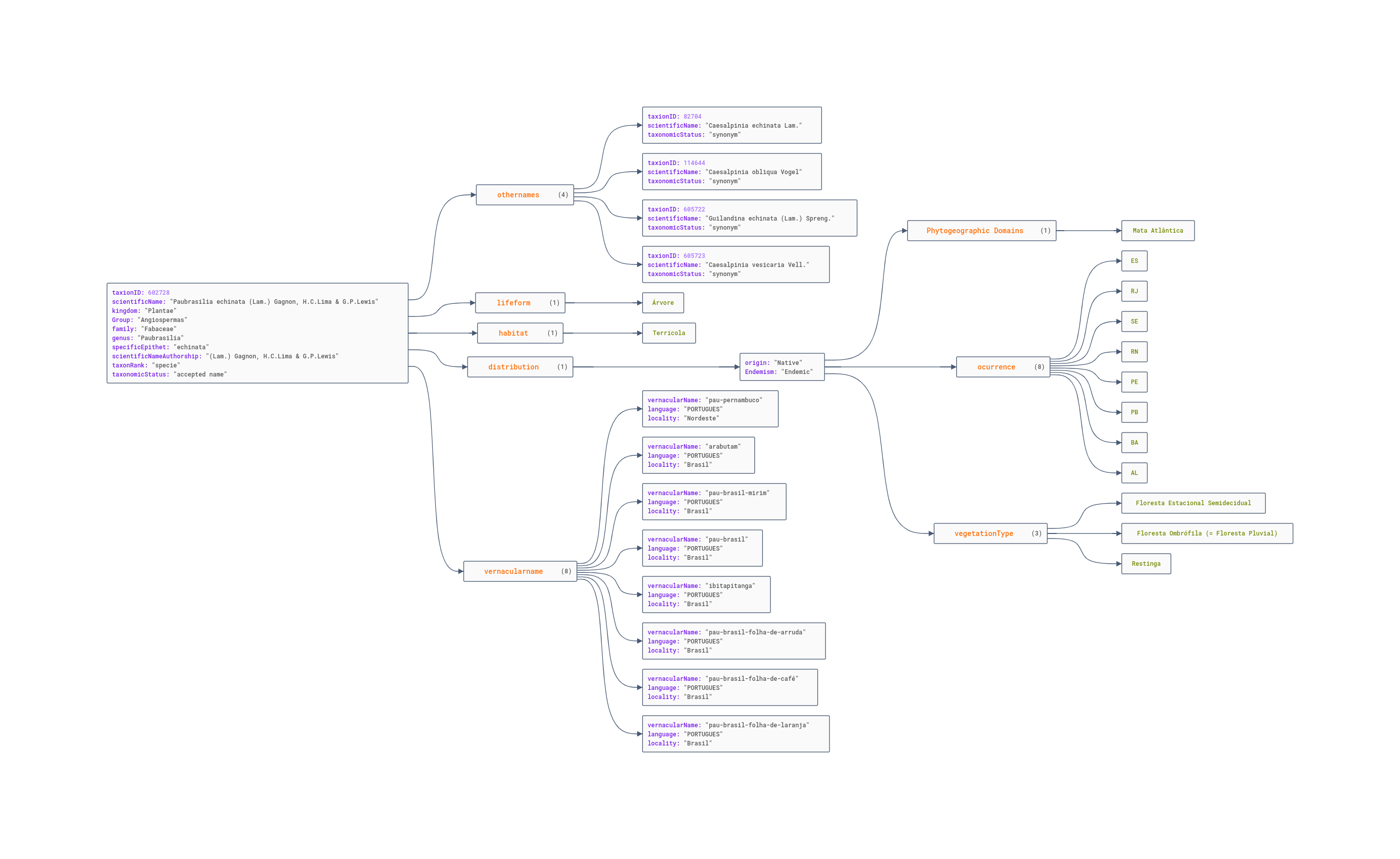<br>
|
||||
[https://jsoncrack.com/editor?json=6416148abbe4fd1e772fdc13](https://jsoncrack.com/editor?json=643968298251297a85d87841)
|
||||
|
||||
É claro que modelar e organizar conjuntos de dados tem que considerar a “implementação”. Ou seja, um “sistema gerenciador de banco de dados” (SGBD) capaz de lidar com a estrutura de dados específica. Lá no artigo sobre grafos comentei que experimente o Neo4J. Para lidar com documentos, tenho brincado bastante com o MongoDB, e estou trabalhando em um projeto para desenvolver uma ferramenta para converter arquivos Darwin Core para o formato JSON, que podem ser gerenciados pelo MongoDB, por exemplo.
|
||||
É claro que modelar e organizar conjuntos de dados tem que considerar a “implementação”. Ou seja, um “sistema gerenciador de banco de dados” (SGBD) capaz de lidar com a estrutura de dados específica. Lá no [artigo sobre grafos](https://eduardo.dalc.in/discutindo-a-relacao/) comentei que experimente o [Neo4J](https://neo4j.com/). Para lidar com documentos, tenho brincado bastante com o MongoDB, e estou trabalhando em um projeto para desenvolver uma ferramenta para converter arquivos Darwin Core para o formato JSON, que podem ser gerenciados pelo MongoDB, por exemplo.
|
||||
|
||||
Porém, o mais fascinante hoje é que estão surgindo soluções de bancos de dados “multi-modelos”, ou seja, que podem lidar com diferentes estruturas de dados (p.ex. grafos, documentos e tabelas) em uma mesma plataforma. Até poucos anos atrás, tínhamos sistemas de “persistência poliglota” (mais de um SDBG), de grande complexidade de implementação e manutenção. Hoje temos alternativas interessantíssimas de SGBDs, capazes de lidar com diferentes modelos de dados, como o ArangoDB, que lida com documentos, grafos e chave/valor; o Fauna (!), que combina o modelo relacional com documentos; e até o “queridinho” dos adeptos do modelo relacional, o PostgreSQL, já admite JSON como um tipo de dados válido em suas tabelas. Ou seja, não é por falta de “implementação” que não estamos avançando em novas, e mais apropriadas, formas de representar dados sobre biodiversidade.
|
||||
|
||||
|
||||
Reference in New Issue
Block a user