mirror of
https://github.com/edalcin/BiodiversidadeDadosMetadados.git
synced 2024-05-15 06:32:48 -03:00
Update 20230321-maldicaoTabelas.md
This commit is contained in:
@@ -5,7 +5,7 @@
|
||||
|
||||
Há algum tempo venho investindo uma parte do meu tempo para ler e aprender sobre novas formas de modelar e estruturar dados. Nestes tempos que vivemos, novas tecnologias estão disponíveis e parece ser razoável considerar novas abordagens para representar o mundo real.
|
||||
|
||||
Acredita-se que as primeiras tabelas surgiram com os sumérios, na antiga Mesopotâmia, há cerca de 2.000 anos, e nossa civilização vem usando esta forma de organizar dados desde então. Desde a mais tenra idade, na escola e, quando adultos, no trabalho, somos condicionados a organizar nossos dados em linhas e colunas. Até aqui, neste editor de texto que vos escrevo (e na maioria dos outros), existe um botão onde posso, rapidamente, criar uma tabela. No maravilhoso mundo dos bancos de dados, as tabelas não só prosperaram como, desde 1970, passaram a se relacionar e, pasmem, deste relacionamento passaram a ter filhos! E, como que por encanto, as “planilhas de cálculo” se tornaram a solução, não para calcular, mas para listar e organizar dados. A presença onipotente das linhas e colunas perverteu até o mais ingênuo e inócuo arquivo digital. O “TXT” virou o “CSV” e passou a frequentar a elite do mundo digital.
|
||||
Acredita-se que [as primeiras tabelas surgiram com os sumérios, na antiga Mesopotâmia, há cerca de 2.000 anos](https://eduardo.dalc.in/wp-content/uploads/2023/03/Marchese_IV11.pdf), e nossa civilização vem usando esta forma de organizar dados desde então. Desde a mais tenra idade, na escola e, quando adultos, no trabalho, somos condicionados a organizar nossos dados em linhas e colunas. Até aqui, neste editor de texto que vos escrevo (e na maioria dos outros), existe um botão onde posso, rapidamente, criar uma tabela. No maravilhoso mundo dos bancos de dados, as tabelas não só prosperaram como, [desde 1970, passaram a se relacionar](https://eduardo.dalc.in/wp-content/uploads/2023/03/codd_relModel.pdf) e, pasmem, deste relacionamento passaram [a ter filhos](https://www.ibm.com/docs/en/spm/8.0.2?topic=cookbook-identifying-entities-patterns-relationships)! E, como que por encanto, as “planilhas de cálculo” se tornaram a solução, não para calcular, mas para listar e organizar dados. A presença onipotente das linhas e colunas perverteu até o mais ingênuo e inócuo arquivo digital. O “TXT” virou o “CSV” e passou a frequentar a elite do mundo digital.
|
||||
|
||||
Entretanto, aprendemos com o “Professor Dalcin”, na primeira aula da disciplina de Gestão de Informação sobre Biodiversidade, que “bancos de dados nada mais são que representações do mundo real” e criar modelos do mundo real com ferramentas limitadas é como tentar representar uma esfera com peças de LEGO®.
|
||||
|
||||
@@ -15,10 +15,10 @@ Chegamos então na provocação central deste artigo. O “paradigma” (odeio e
|
||||
|
||||
Sem dúvida alguma, conjuntos de tabelas relacionadas tem seu papel na organização de dados sobre biodiversidade. O que é diferente de dizer que todos os dados sobre biodiversidade são bem representados por conjuntos de tabelas relacionadas.
|
||||
|
||||
Alguns conjuntos e dados sobre biodiversidade podem ser melhor representados sob a forma de grafos, como já comentei nesta postagem aqui. E, outra forma de estruturar dados bem popular hoje em dia é sob a foma de documentos, onde o formato mais conhecido é o JSON (JavaScript Object Notation), o filho “celebridade” do XML. Abaixo um exemplo de documento JSON, contendo dados sobre uma espécie:
|
||||
Alguns conjuntos e dados sobre biodiversidade podem ser melhor representados sob a forma de grafos, como já comentei [nesta postagem aqui](https://eduardo.dalc.in/discutindo-a-relacao/). E, outra forma de estruturar dados bem popular hoje em dia é sob a foma de documentos, onde o formato mais conhecido é o [JSON (JavaScript Object Notation)](https://www.w3schools.com/js/js_json_intro.asp), o filho “celebridade” do XML. Abaixo um exemplo de documento JSON, contendo dados sobre uma espécie:
|
||||
|
||||
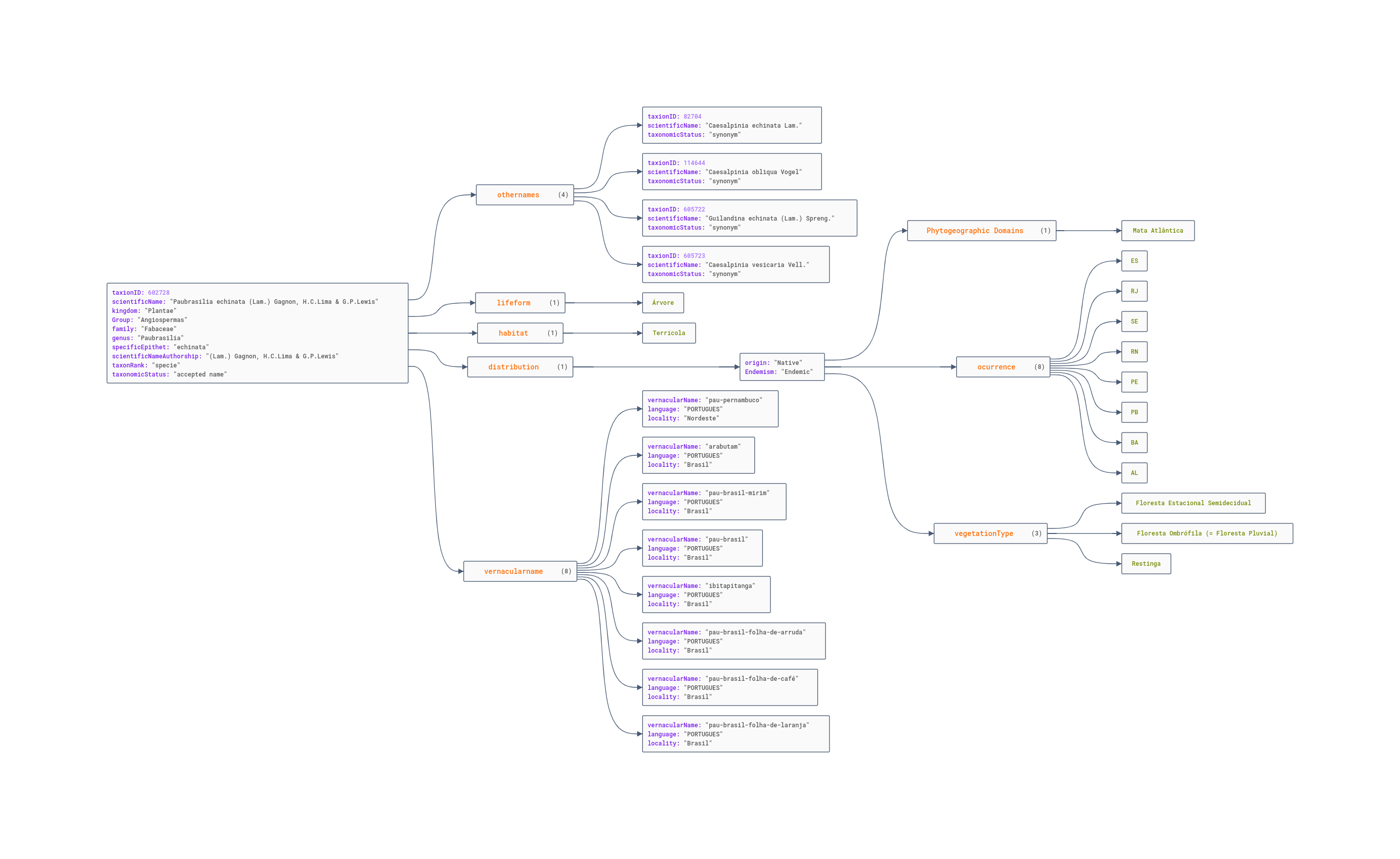<br>
|
||||
https://jsoncrack.com/editor?json=6416148abbe4fd1e772fdc13
|
||||
[https://jsoncrack.com/editor?json=6416148abbe4fd1e772fdc13](https://jsoncrack.com/editor?json=643968298251297a85d87841)
|
||||
|
||||
É claro que modelar e organizar conjuntos de dados tem que considerar a “implementação”. Ou seja, um “sistema gerenciador de banco de dados” (SGBD) capaz de lidar com a estrutura de dados específica. Lá no artigo sobre grafos comentei que experimente o Neo4J. Para lidar com documentos, tenho brincado bastante com o MongoDB, e estou trabalhando em um projeto para desenvolver uma ferramenta para converter arquivos Darwin Core para o formato JSON, que podem ser gerenciados pelo MongoDB, por exemplo.
|
||||
|
||||
|
||||
Reference in New Issue
Block a user