13 KiB
Usando Arquivos Darwin Core
⚠️ Este guia é destinado a pesquisadores e demais interessados em utilizar dados publicados no formato Darwin Core Archive em repositórios públicos "IPT". O guia é destinado a usuários sem conhecimentos avançados sobre este tema.
Qualquer pesquisador que necessite de dados sobre biodiversidade em seus projetos de pesquisa já ouviu falar de "Darwin Core" (DwC). Não pretendo entrar em detalhes aqui sobre o padrão em si, pois ele é tratado coim mais detalhes aqui nesta publicação da livraria. A ideia aqui é dar uma visão prática, um passo-a-passo de como "baixar", e usar os dados no formato Darwin Core Archive (DwC-A) publicados no IPT (Integrated Publishing Toolkit).
Entendendo alguns conceitos
Creio que o primeiro ponto de esclarecimento necessário aqui é o que estou chamando de "padrão Darwin Core", que usamos a sigla "DwC"; e o "formato Darwin Core Archive", para o qual vamos usar a sigla "DwC-A".
Padrão Darwin Core (DwC) - é um conjunto de termos com suas definições, associados a identificadores únicos e organizados em classes, destinados a facilitar o compartilhamento de informações sobre diversidade biológica. Formato Darwin Core Archive (DwC-A) - é um conjunto de arquivos digitais em formatos específicos incluídos em um arquivo "ZIP" e disponibilizado para "download" em um "Repositório IPT".
Repositório IPT - é um conjunto de páginas na Internet onde estão disponíveis para download os arquivos de dados no formato DwC-A.
Encontrando arquivos DwC-A com dados
Os arquivos DwC-A são publicados - ficam disponíveis para download - nos repositórios IPT das instituições. Aqui vão alguns exemplos:
- IPT das coleções do Instituto de Pesquisas Jardim Botânico do Rio de Janeiro (JBRJ)
- IPT do JABOT - Sistema Gerenciador de Herbário do JBRJ com várias coleções
- IPT do REFLORA
- IPT do O Sistema de Informação sobre a Biodiversidade Brasileira (SiBBr)
Arquivos DwC-A podem ser gerados como resultado de consultas à base de dados do Global Biodiversity Information Facility (GBIF).
Vamos usar aqui, como exemplo, o recurso "Projeto Flora do Brasil 2020" do IPT das coleções do Instituto de Pesquisas Jardim Botânico do Rio de Janeiro (JBRJ).

Clicando no nome do recurso (figura acima) você vai visualizar a página do recurso, com várias informações sobre o recurso, como, por exemplo, sua descrição, frequência de atualização, número da versão atual, acesso às versões anteriores e como citar o recurso.
Vai encontrar também a seção de "downloads" conforme a figura abaixo:

Clicando em "download" da opção "Data as a DwC-A file" você irá salvar no seu computador o arquivo DwC-A. Entendendo o arquivo "Darwin Core Archive" (DwC-A) Como dito anteriormente, o arquivo DwC-A é um arquivo "ZIP", ou seja, um arquivo que contém, internamente, vários arquivos. Na figura abaixo você pode visualizar a estrutura básica do arquivo DwC-A:
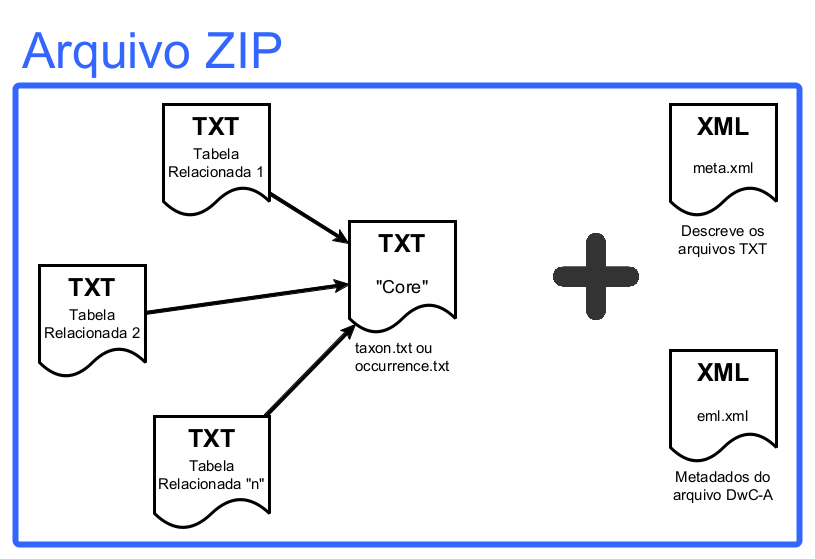
Como pode ver, o arquivo DwC-A é composto de dois conjuntos de arquivos: arquivos com extensão "TXT" e arquivos com extensão "XML". Os arquivos meta.xml e eml.xml são arquivos de "metadados" - são dados sobre o conjunto de dados (o arquivo eml.xml) e sobre os arquivos ".TXT" que contem os dados (o arquivo meta.xml). Os arquivos em formato "XML" são destinados a serem lidos e interpretados "por máquinas", ou seja, de forma automatizada por outros computadores. Assim sendo, não vamos detalhá-los aqui neste guia. Os arquivos "TXT", entretanto, são aqueles que contém os dados em si. Desta forma, vamos nos dedicar a estes. Os arquivos ".TXT" contidos dentro do arquivo DwC-A são, na verdade, tabelas representadas no arquivo por linhas (os registros) e colunas (os atributos destes registros). No caso dos arquivos gerados automáticamente pelo IPT, as colunas estão separadas por tabulações. Desta forma, são arquivos conhecidos como arquivos "Tab Separated Values" (TSV), diferentes dos aquivos ".CSV", onde as colunas são separadas por vírgulas.
Os arquivos TXT
O conjunto de arquivos TXT dentro do arquivo "ZIP" do DwC-A pode ser de dois tipos:
- Um conjunto de arquivos sobre ocorrência
- Um conjunto de arquivos sobre espécies
- Um conjunto de arquivos sobre amostragem (não serão tratados neste guia)
Este conjunto de arquivos TXT, por sua vez, possui dois tipos de arquivos: o "núcleo" (core) e as "extensões" (extension).
O que define se os dados no arquivo DwC-A são sobre espécies ou sobre ocorrências destas espécies é o seu núcleo, ou core. Se houver um arquivo "taxon.txt" dentro do arquivo ZIP, este conjunto de dados é sobre espécies - na maioria das vezes um checklist ou lista de espécies; se houver um arquivo "ocurrence.txt" dentro do arquivo ZIP, este conjunto de dados é sobre a ocorrência de espécies - geralmente dados de exsicatas de herbário ou coleções científicas.É importante notar também que as extensões (os outros arquivos TXT que não o taxon.txt nem o occurrence.txt) são dependentes do núcleo. Ou seja, caso o conjunto de dados seja sobre espécies (com o núcleo taxon.txt), os demais arquivos TXT serão sobre características destas espécies, por exemplo, seus nomes vulgares. Caso o conjunto de dados seja sobre ocorrências (com o núcleo ocurrence.txt), os demais arquivos TXT terão dados adicionais sobre estas ocorrências, por exemplo, o link para a imagem da exsicata ou do indivíduo na coleção.
Conjunto de dados sobre espécies
Vamos usar como exemplo aqui os arquivos de dados da Flora e Funga do Brasil, disponíveis neste link do IPT.
O arquivo DwC-A disponível na página do recurso no IPT terá o nome "dwca-lista_especies_flora_brasil-vXXX.XXX.zip", onde "XXX.XXX" será correspondente ao número da versão do arquivo.
Dependendo do recurso - a base de dados que o arquivo DwC-A representa - o IPT pode gerar, periodicamente, novas versões do arquivo DwC-A, que acompanham a atualização da base de dados. No exemplo da Flora e Funga do Brasil, um novo arquivo é gerado semanalmente, e as versões anteriores também continuam disponíveis para download e referência.
Ao abrir o arquivo ZIP, você vai encontrar os seguintes arquivos:
| Arquivo | Categoria | Descrição |
|---|---|---|
| eml.xml | Metadados | Arquivo que descreve o conjunto de dados. Ele segue o padrão Ecological Metadata Language (EML) |
| meta.xml | Metadados | Arquivo que descreve o conteúdo do arquivo "núcleo" e dos arquivos de extensão |
| taxon.txt | Núcleo | Arquivo que contêm a lista das espécies com outros dados (p.ex. hierarquia taxonômica, status nomenclatural, etc.) |
| distribution.txt | Extensão | Arquivo que contém dados sobre a distribuição das espécies listadas no arquivo "taxon.txt" |
| reference.txt | Extensão | Arquivo que contém dados sobre a distribuição das espécies listadas no arquivo "taxon.txt" |
| resourcerelationship.txt | Extensão | Arquivo que contém dados sobre relação entre os nomes das espécies listadas no arquivo "taxon.txt". Neste exemplo, contem dados sobre o tipo de sinonímia |
| speciesprofile.txt | Extensão | Arquivo que contém dados adicionais das espécies listadas no arquivo "taxon.txt", Neste exemplo, estão listados dados sobre a "forma de vida" e "habitat" |
| typesandspecimen.txt | Extensão | Arquivo que contém dados sobre os typus das espécies listadas no arquivo "taxon.txt" |
| vernacularname.txt | Extensão | Arquivo que contém dados sobre nomes vulgares das espécies listadas no arquivo "taxon.txt" |
⚠️ Dependendo do recurso - a base de dados que o arquivo DwC-A representa - os arquivos de extensão podem variar.
No caso dos arquivos DwC-A que representam a Flora e Funga do Brasil, disponíveis no IPT do JBRJ, é importante destacar que nem todos os dados disponíveis no Sistema Online da Flora e Funga do Brasil estão disponíveis no seu arquivo DwC-A.
Conjunto de dados sobre ocorrências
Vamos usar como exemplo aqui os arquivos de dados do Herbário do Instituto de Pesquisas Jardim Botânico do Rio de Janeiro (exsicatas), disponíveis neste link do IPT. O arquivo DwC-A disponível na página do recurso no IPT terá o nome "dwca-jbrj_rb-vXXX.XXX.zip", onde "XXX.XXX" será correspondente ao número da versão do arquivo. Ao abrir o arquivo ZIP, você vai encontrar os seguintes arquivos:
| Arquivo | Categoria | Descrição |
|---|---|---|
| eml.xml | Metadados | Arquivo que descreve o conjunto de dados. Ele segue o padrão Ecological Metadata Language (EML) |
| meta.xml | Metadados | Arquivo que descreve o conteúdo do arquivo "núcleo" e dos arquivos de extensão |
| occurrence.txt | Núcleo | Arquivo que contêm a lista de exsicatas (amostras) com outros dados (p.ex. local de coleta, coletor, data de coleta, etc.) |
| identification.txt | Extensão | Arquivo que contém dados sobre o histórico de determinação de cada exsicata listada no arquivo "occurence.txt" |
| multimedia.txt | Extensão | Arquivo que contém dados sobre as imagens associadas com as exsicatas listadas no arquivo "occurence.txt" |
⚠️ Dependendo do recurso - a base de dados que o arquivo DwC-A representa - os arquivos de extensão podem variar.
O que fazer com estes arquivos TXT
Conforme citado anteriormente, estes arquivos, quando gerados automaticamente pelo IPT, são "tabelas separadas por tabulações" (TSV). Desta forma eles podem ser carregados para sistemas de Planilhas, como EXCEL, da Microsoft; o CALC, do LibreOffice ou OpenOffice; ou o Planilhas, do Google. Veja como abaixo, usando como exemplo um conjunto de dados sobre espécies:
Abrindo os arquivos TXT com Excel
Abrindo os Arquivos TXT com Excel Para abrir corretamente os arquivos TXT no Excel siga os passos:
- Clique em "Abrir"
- Clique em "Procurar"

- Escolha o tipo de arquivo correto: "Arquivo de texto"
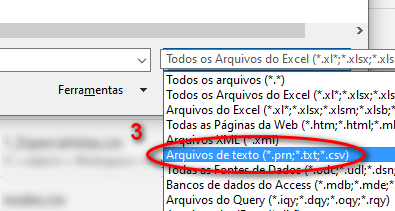
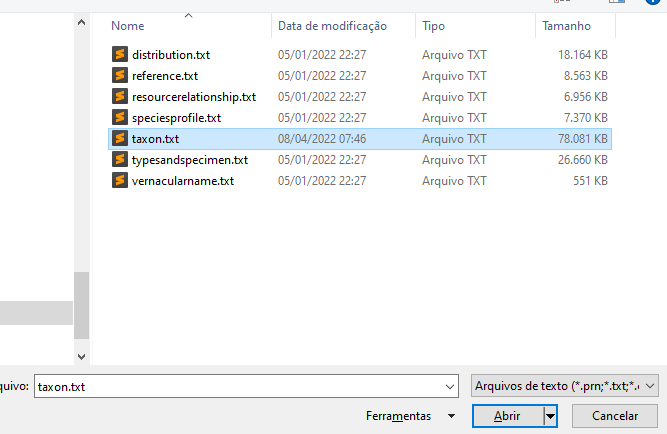
- Escolha um dos arquivos para abrir: "taxon.txt"
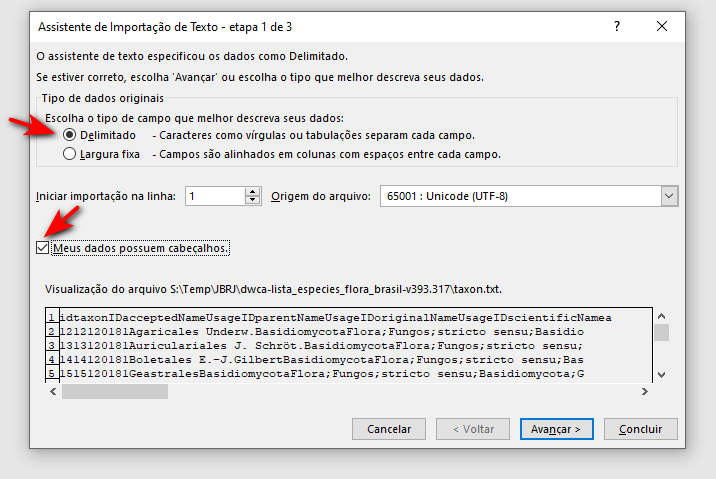
- Marque as opções "Delimitado", "Meus dados possuem cabeçalhos" e "Avançar"
- Marque a opção "Tabulação" e "Concluir".
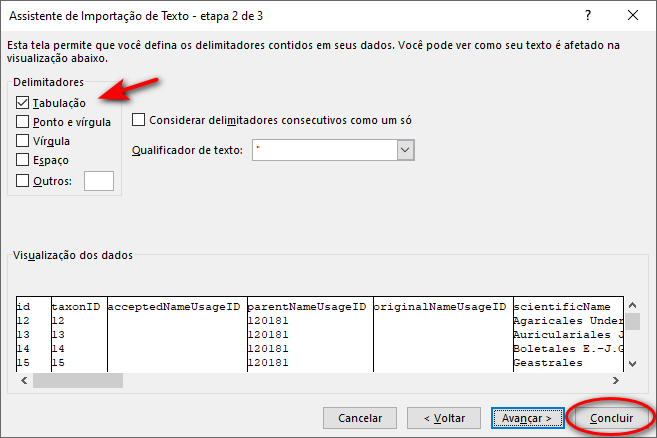
Pronto! Seus dados estão no EXCEL!
Importando o arquivo TXT para o Google Planilhas
- Crie uma planilha em branco e escolha "Arquivo" → "Importar"
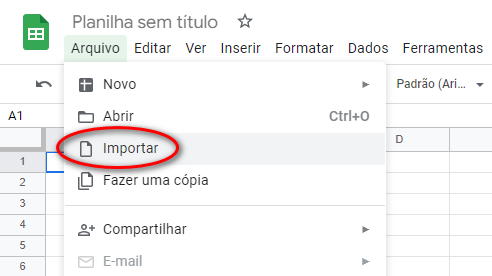
- Escolha o arquivo e aguarde a importação
- Mantenha as opções "Substituir planilha", "Detectar automaticamente" e "Converter textos em números, datas e fórmulas":
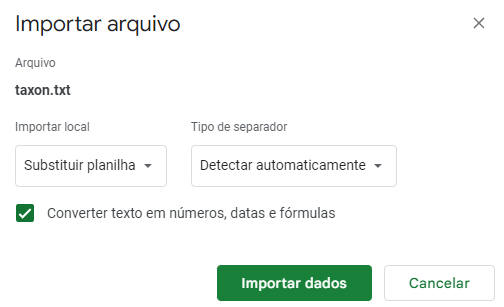
Aguarde o final da importação. Pronto! Seus dados estão no Google Planilhas.
⚠️ No caso da arquivo "taxon.txt" da Flora e Funga do Brasil, o tamanho do arquivo (quantidade de linhas e colunas) pode causar problemas na importação. Se retornar uma página em branco, sugiro voltar para a página principal e clicar no arquivo recém criado.
Relacionando as tabelas
É importante notar que, conforme dito anteriormente, os arquivos TXT que representam as extensões se relacionam com o "arquivo-núcleo" através da coluna "taxonID", conforme ilustrado abaixo:

Este relacionamento a forma com que os dados são organizados no banco de dados do Sistema da Flora e Funda do Brasil. Entretanto, estabelecer estas relações usando um programa de "Planilhas Eletrônica", como o EXCEL, ou qualquer outro sistema de planilha, é um grande desafio para usuários sem conhecimentos avançados. Estas relações são melhor estabelecidas e mantidas em um sistema de banco de dados, em um sistema de "planilhas relacionais", tipo GRIST; ou podem ser estabelecidas também por programação.
Links relevantes
Comentários e críticas são sempre bem-vindos, neste link: https://forms.gle/4mtd7cv7Bx6o5xC68
⚠️ Os textos e conteúdo aqui publicados estão sob a licença Creative Commons de Atribuição 4.0 Internacional (CC BY 4.0).